The setup
RoboHack2026 is the first iteration of a robotics-based hackathon organized by AI Team (https://epflaiteam.ch/). You get one robot and 36 hours, as well as tons of tools to impress a jury. We were given a LeRobot SO-101 that we had to assemble first. The last time I built my own hardware was in high school, so I was glad my teammates were able to offset my weaknesses here. Getting it up and running after 4 hours was such a relief, and playing around with teleoperation is a lot of fun!
Collecting data
After playing around with teleoperation to better gauge what kind of task we want to tackle, we decided on a keyhole insertion task. For this, we modified the default gripper with an extension, as well as the two workpieces that are supposed to be interlocked. This is all 3D-Printed.
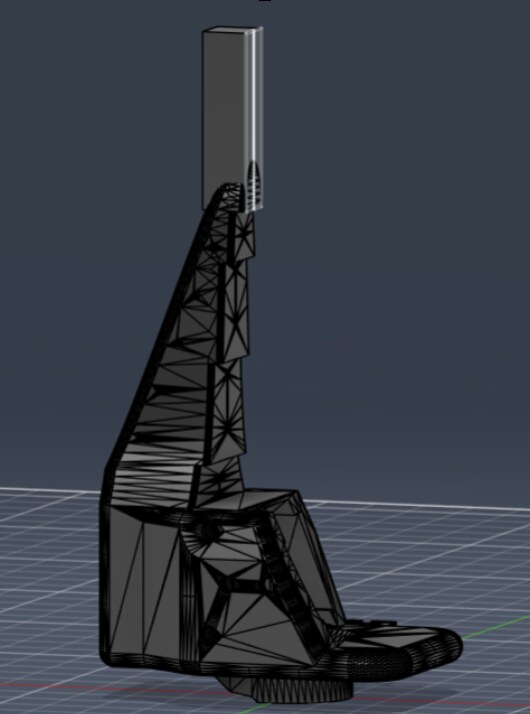
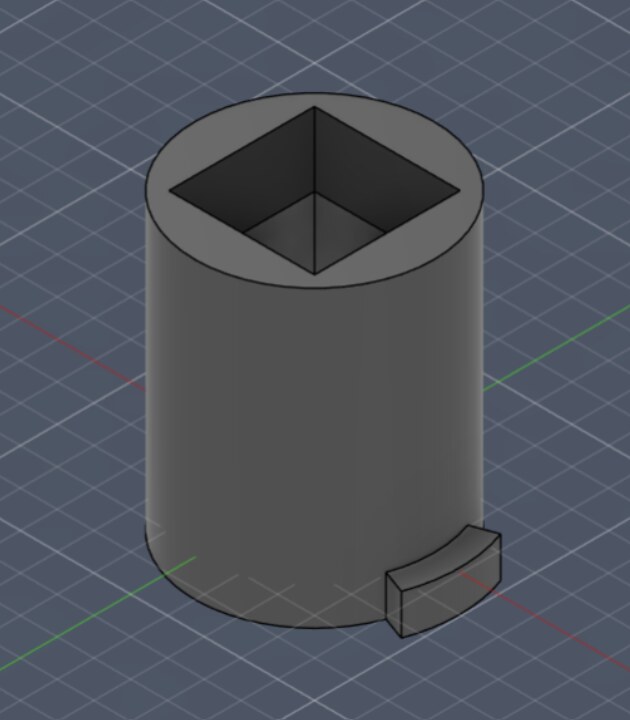

After setting it all up, it looked like this:

We had some spare Monitors we didn’t need that ended up being the backdrop for our scene. Because we wanted to use a second camera for higher precision, we ended up sacrificing one of our teammate’s laptops. It can see almost all of the robot’s configuration space. The wrist camera is professionally duct-taped close to the endeffector.
Training the model
We tried playing around with VLAs, but it it was simply overkill and we already took quite a big risk with our task choice. We decided to move forward with ACT. At this point, the idea is simply to record 50-100 demos, and gamble on the fact that a last-minute training run will yield a model with a success rate larger than 0%.
So we spent a couple hours setting up our data collection pipeline, double and triple checking to make sure our dataset looks good before committing an hour on just recording data.
To hedge our bet, we trained 4 models: One on AWS, one on Huggingface, one on my university’s cluster and one on runpod. All on different hyperparameters.
These are the most note-worthy models:
| Model | Dataset | Batch | Steps | Final loss |
|---|---|---|---|---|
| A | 50 demos | 16 | 60K | 0.04 |
| B | 110 demos | 128 | 15K | 0.072 |
Last-Minute Evaluation
On Sunday, our team barely slept 3-4 hours. We got up at around 10AM to evaluate the model we’d present at 1PM. One of the first fully on-policy runs was this one:
After an exhausting 33 hours of hacking, we were literally shaking, partying and hugging. Our gamble worked out and the policy was actually able to solve the task! This moment alone made everything worth it.
Now it was all about trying to measure how good our policy actually was. We measured a success rate of around 26%, and an initial pick-up rate of 80% for Model A. Ironically, Model B performed much worse, even though it saw a lot more data. I think the error was that I did not adjust learning rate after increasing batch size (the GPU was much more capable than the one for model A), but really who knows what I even did on this bender of a debugging session at 5:30AM in the morning on a combined 4h of sleep from the previous night.
Closing Remarks
Even though the other teams built some very strong demonstrations, we actually managed to convince the judges and win!
The entire experience was extremely rewarding and I want to thank my Team: Jonas Clotten, Giacomo Galbiati, and Simone Redaelli. Between EPFL, the city itself and the sceneray around it, I think Lausanne is such a beautiful place. I want to thank everyone from AITeam @ EPFL who organized this amazing event. Without them, I never would have had the privilege of visiting.